Migrating Savory to a serverless backend
- Authors

- Name
- Akshay Kumar
- @akshaykumar90
- Published on
Savory is a web app to organize and manage your long reading list, bookmarks and references. Since launch in May 2020, Savory has used MongoDB Realm for its backend, which was nothing more than a lightweight wrapper over the underlying MongoDB Atlas cluster, with some custom authorization rules sprinkled on top.
The original backend design, or the lack thereof, was good enough when we were just getting started. But as the number of bookmarks grew, performance issues started showing up. Page load time shot up to double-digit seconds for me (6000+ bookmarks). This is partly because I am in India and the database is hosted on the other side of the world in Oregon, US. But one of the major self-inflicted problems with the design was that we were loading and returning all the bookmarks for a user from the database at page load. Yes, all 6000 of them in my case. Every time.
I recently landed a chonky commit in Savory’s repo to migrate us to a serverless backend and the accompanying frontend re-architecture. Hard refresh page load time came down to 3-4 seconds, and the time-to-interactive is just over a second.
In this post, I talk about the backend. In a future post, I will write about the frontend architecture before-and-after.
Why was it slow?
Let’s go back in time to summer of 2018. Savory started as a replacement for Chrome’s stock bookmark manager. It was just a pretty interface over your browser’s bookmarks. Later, we added tags and better search behavior, and eventually moved out of Chrome and launched as a standalone web app at app.getsavory.co. Savory’s frontend architecture did not keep up, and staying close to its bookmark manager roots, expected everything to exist locally when it loads up. This worked well when we were just calling browser API’s to load bookmarks, but not when the bookmarks are stored in a database in cloud.
To make things worse, Savory made multiple requests to the backend at page load—one for each database query—to retrieve resources like user info, bookmarks count and the actual bookmarks. The uncompressed bookmarks json response could easily creep into double-digit MiBs. Some of these requests were parallelized, but the overall frontend app was not useful until the first few completed successfully.
We need a backend
By having a proper backend, we can expose a backend-for-frontend API which can serve the minimal content required for a functional user experience. This would also unblock SSR in a later iteration.
Having a proper backend is also desirable to decouple frontend app deployments from frequent backend changes. This is especially relevant to us since one of Savory’s frontend app is a Chrome extension where each deployment needs review from Chrome Web Store team before publishing.
Anyway, we need a backend. It is 2020—this should not be too hard. I started looking for one in late September this year.
Since this is just a side-project (for now), we are looking for backend platforms with a generous free tier. And we still need a database. MongoDB Atlas, which is what we are using currently, is a hosted MongoDB database cluster with a good-enough free tier. Where do we host the compute though?
Free tier MongoDB Atlas can be opened up to allow connections from static IP address blocks. But serverless hosting providers like Vercel do not offer static IP’s. And the workaround of opening up the cluster to the entire Internet (with username/password authentication) was just too risqué for me.
As it happens, MongoDB Realm also offers serverless functions. Well hello, vendor lock-in. The product is called Realm Functions and I decided to move forward with it to keep things simple. I am happy to report that Savory now runs on top of Realm Functions as its backend.
Mind the serverless gap
It was an interesting (read: not-great) experience for me, in part due to this being my first brush with serverless. In addition, I decided to write the backend in TypeScript. For context, I have significant experience implementing classical backend in languages like Java, Python and Ruby.
non-standard runtime environment
Realm Functions runtime environment is non-standard and under-specified. The documentation mentions that it is compatible with Node 10.18.1 and you can use most modern (ES6+) JavaScript features in functions, including async/await, destructuring, and template literals. But, not all of them. For example, Proxy and WeakSet are not supported. I was already using Proxy in some auth-related code on the frontend and I wanted to share it with the backend but couldn’t do so.
wtb packaging best-practices
There are no best practices around packaging your serverless functions. My functions were simple. They do a few database lookups and combine the output before returning. I started out by writing functions as was recommended in the docs. Soon, I realized that I was repeating a lot of code across these functions.
Like any other self-respecting developer, I do not like repeating a chunk of code more than twice (twice is fine, trust me). Therefore, I decided to use webpack to bundle the code for each serverless function from a common input codebase. Essentially, in the webpack config file, I specify one output for each serverless function. At build time, webpack can bundle each function and use tree-shaking to eliminate code which is not used in that function. (It also will reduce size by minification/uglifying but that was not the goal and can be turned off.)
entry: {
addTag: ['./src/addTag.js'],
createBookmark: ['./src/createBookmark.js'],
...
}
This did not work (or at-least will not work short of writing a custom plugin for webpack). Realm Functions require that a function must be assigned to the global variable exports for each Realm Function definition. The closest I could get to a solution was by setting output.libraryTarget to var, but even then the thing which would get assigned to the global variable is a UMD module, and not a function.
At this point, I decided to create a private npm package for my service. The serverless function definition would require this package and then call the actual function. The npm package would be uploaded to Realm Functions on every deployment. This works, but is non-optimal for a couple of reasons. I still need to hand-write the actual serverless function which imports this package and calls the actual function. For example, for the addTag serverless function, I have to write a shim like this:
exports = (tagName, bookmarkId) => {
const savory = require('savory')
return savory.app.handle('addTag', [tagName, bookmarkId])
}
There is also no tree-shaking happening here. Every function call will have to require the savory package at runtime, which will make the function invocation slow as we add more stuff to the package, even when it is unrelated to the code required for adding a tag.
Also, notice the position of the require expression in this code. The
non-standard environment bites us again. From the docs:
Node.js projects commonly place require statements in the global scope of each file, but Realm does not support this pattern. You must place Realm Function require statements within a function scope.
we will test in production
Testing serverless functions locally is already pretty hard. Realm Functions make it worse owing to the non-standard runtime environment they run in. I cannot replicate the environment locally, and will have to rely on testing in production. This slows down development velocity because I have to upload the npm package and then wait for a deployment before the tests can run. I don’t think there are any local testing environments available specifically for MongoDB Realm Functions.
warming up to serverless
The last thing to note is that serverless functions are slow. The simplest function (and all of them are pretty simple at this point) take more than a second. That’s an eternity!
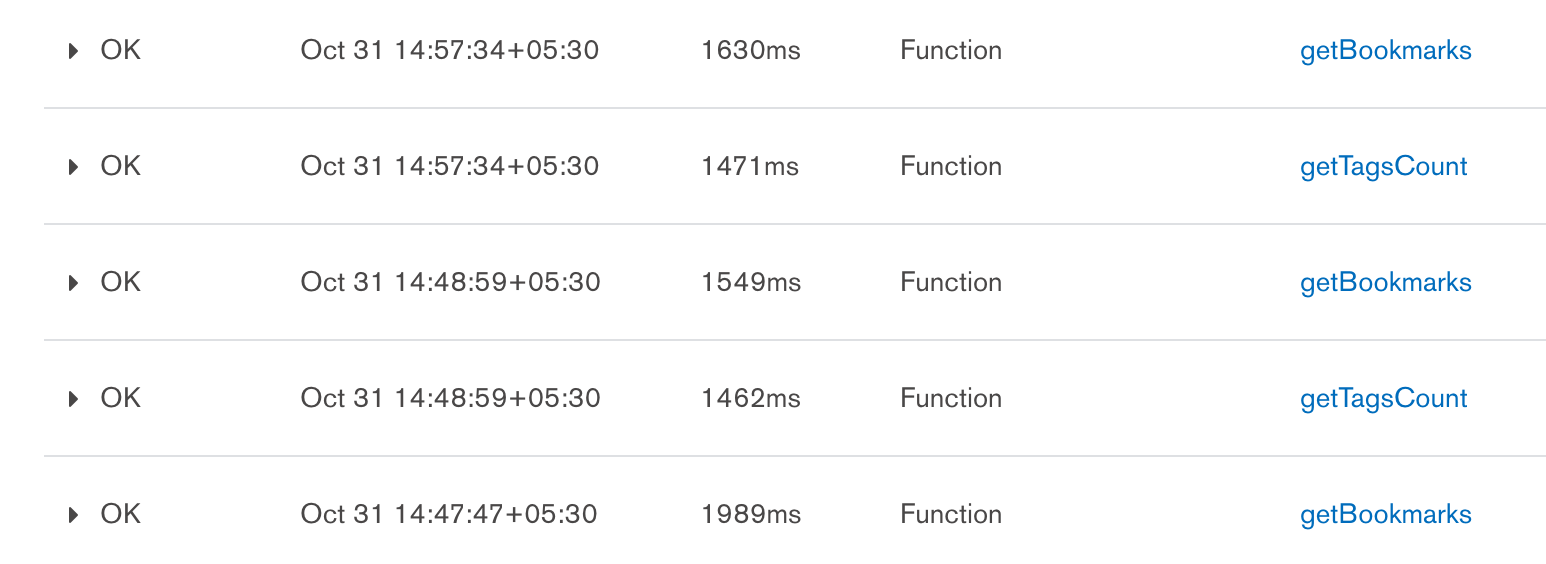
I am not sure why but these runtimes are slow even when taking cold start into account. In practice, serverless functions, after they have run once, should remain warm for an undetermined period of time. But that’s not what we see here. The getBookmarks function for example was called within a minute and still took 1.5s to compute.
Wrapping up
Some of these problems are specific to MongoDB Realm, which is not as widely used as some other serverless platforms like AWS Lambda. But issues with local testing and performance are common to all such platforms.
Even though I just finished this migration, and it is an improvement over what we had before, I am not quite satisfied with the performance. We are still pretty small and nimble, and the backend can be ported to something else in the future relatively painlessly. The decoupling of frontend and backend will also help a lot in any future migration.
I also looked at some alternative backend platforms for this migration. DigitalOcean App Platform also does not provide dedicated IP address and therefore cannot be used with MongoDB Atlas. It also cannot be used together with their own hosted database offering which is a shame. fly.io has no support for database either; it is aimed at compute-only use-cases like image, video processing etc.